Data Preparation
Selecting columns of season, teamName, playerName, position, rating, game_minutes, key_pass, pass_accura, and fouls_drawn in the player dataset. Calculating duel success rate by duel_won/duel_total, and computing dribble success rate by dribble_success/dribble_attemp. Then picking players whose position in the midfielder and season from 2020 to 2022. There are some NaN values due to some players being transfeered out by clubs at the beginning of the season, so dropping these NaN values. After that, generating a new data frame.
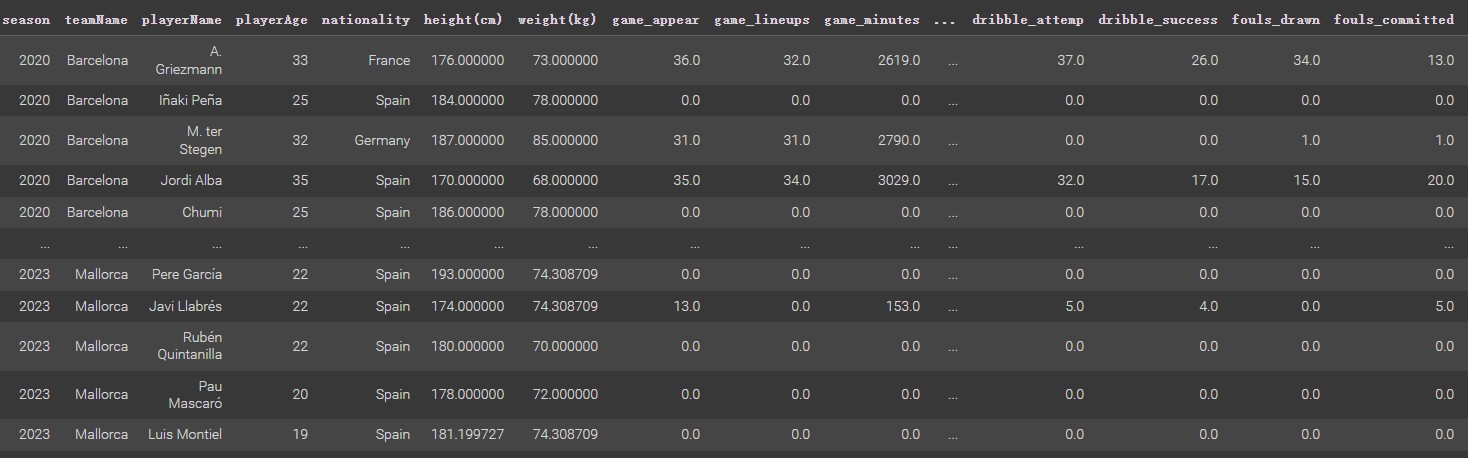
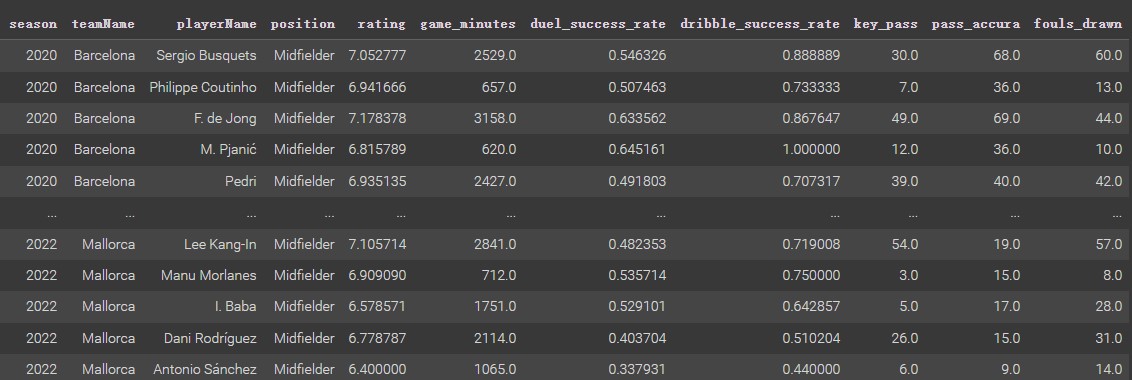
Since the new dataset not have a category column. Thus, using K-means based on numeric variables of rating, game_minutes, key_pass, pass_accura, fouls_drawn, duel_success_rate, and dribble_success_rate. The k value used here is 2 (categries: Good and Normal). After K-mean clustering processing, the label columns is merged into the new dataset, as shown below. (Same processing as Decision Tree Section)
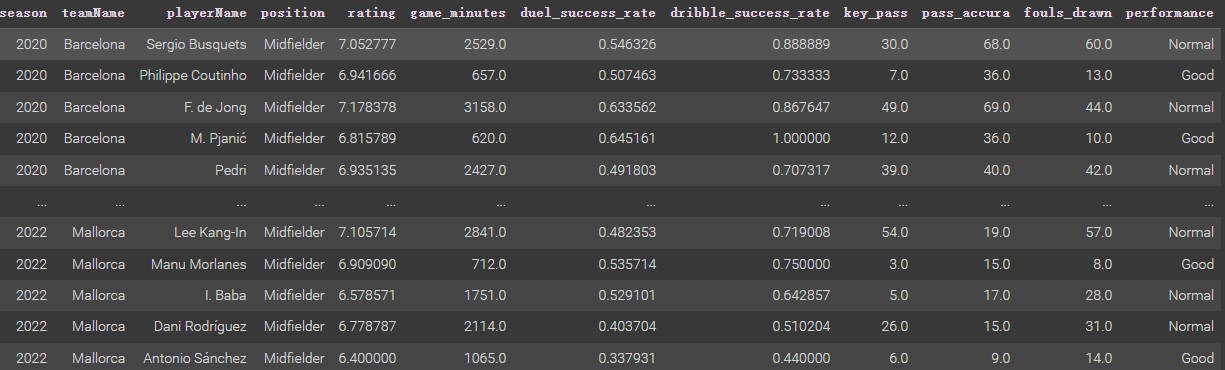
Train Dataset & Test Dataset Splitting
playerTrainDF, playerTestDF = train_test_split(player,test_size = 0.3, random_state=42)
playerTrainDF.to_csv("DTTrainDF.csv")
playerTestDF.to_csv("DTTestDF.csv")
print(playerTrainDF)
print(playerTestDF)Also using the train_split function as same in the Multinomial NB section&Decision Tree, and getting the train dataset and test dataset. Here the test is divided into 30% of the new dataframe. Also, use reandom_state=42 to ensure that the train set and test set do not change once running code every time. Creating a disjoint split is essential for the prediction model. If there are overlapping samples in the training set and test dataset, the model will view the labels in the test set and remember them during training. It can lead to errors in the evaluation of the performance of the model. Just as a student knows the answers to an exam in advance, a teacher cannot determine whether this student has really learned content by the test score.
Using the code below to check whether train set and test set disjoint splitting or not.
# Check Train and Test sets are disjoint
if not disjoint_check.empty:
print("Train and Test set have same rows")
else:
print("Train and Test set have not same rows") |
 |
|---|---|
| The Train DatasetTrain Set | The Test DatasetTest Set |
After that, the train set and test will be fine-tuned using the following code in preparation for use with the support vector machine algorithm.
playerTestLabel = playerTestDF['performance']
playerTestDF = playerTestDF.drop(['performance'],axis = 1)
playerTrainDF_nolabel = playerTrainDF.drop(['performance'],axis = 1)
playerTrainLabel = playerTrainDF['performance']
dropcols = ['season','teamName','playerName','position']
playerTrainDF_nolabel_quant = playerTrainDF_nolabel.drop(dropcols,axis = 1)
playerTestDF_quant = playerTestDF.drop(dropcols,axis=1)Resource
Support Vector Machine Data Preparation Code: Python Code
